Dato che il mio amichino Theo mi suggeriva che forse a qualcuno potrebbe interessare un tutorial su come installare e configurare Nagios, stavo pensando di iniziare un corso su Nagios articolato, per ora, nei seguenti step:
1. Avvicinamento. Cosa è Nagios, a cosa mi può servire, cosa fa;
2. Hands on. Prendiamo i sorgenti di Nagios, compiliamoli e installiamolo su un server. Partirò da una virtual machine Ubuntu Desktop pulita, indicandovi quali pacchetti o programmi o librerie accessorie installare e come farlo. Parto da una Destkop, tanto per non farvi ammattire;
3. Test the difference. Seconda macchina virtuale. Questa sarà il client Ubuntu che terremo sotto controllo, su questa installeremo gli agenti e impareremo a configurarne il supporto SNMP;
4. Win on Win. Impareremo a installare, configurare e interrogare il clent Nsclient++, in modo da tenere sotto controllo anche le macchine Windows. Davvero pensavate che avrei ignorato Windows?
4. So confusing, so amazing. Giusto un po’ di teoria. I file principali di Nagios, la loro sintassi, il significato delle varie istruzioni. Questo punto richiederà probabilmente una serie di puntate a parte;
5. Creiamo il nostro primo plugin. Si, si, giusto un paio di api, un po’ di bash, e si fa tutto. Imparerete a estendere Nagios oltre ogni vostra immaginazione. Ok, frase ad effetto ma rende l’idea.
6. Agentless! SNMP mon amour. Ok, vedremo come configurare Net-Snmp, come interrogarlo in maniera sicura, come gestire delle trap, insomma, come fare parecchie cose interessanti senza bisogno di installare un agente sulla macchina da tenere sotto controllo;
7. GraphITe! Plottare Nagios. I dati di per sé sono nulla se non li aggreghi in qualche modo. Vedremo come generare dei grafici partendo dai dati recuperati da Nagios. Cosa useremo? Mah, io ho sempre utilizzato NagiosGrapher, ma anche Pnp4Nagios potrebbe andare bene;
8. Templare! Ok, non è una religione. Se i template base di NagiosGrapher non vi bastano, vedremo come crearne qualcuno a nostro piacimento, con tanto di legende, linee mediane e quant’altro.
9. Infighettiamoci. Beh, Nagvis fa sempre scena, vedremo come mettere Nagios sul palco e ben sotto i riflettori.
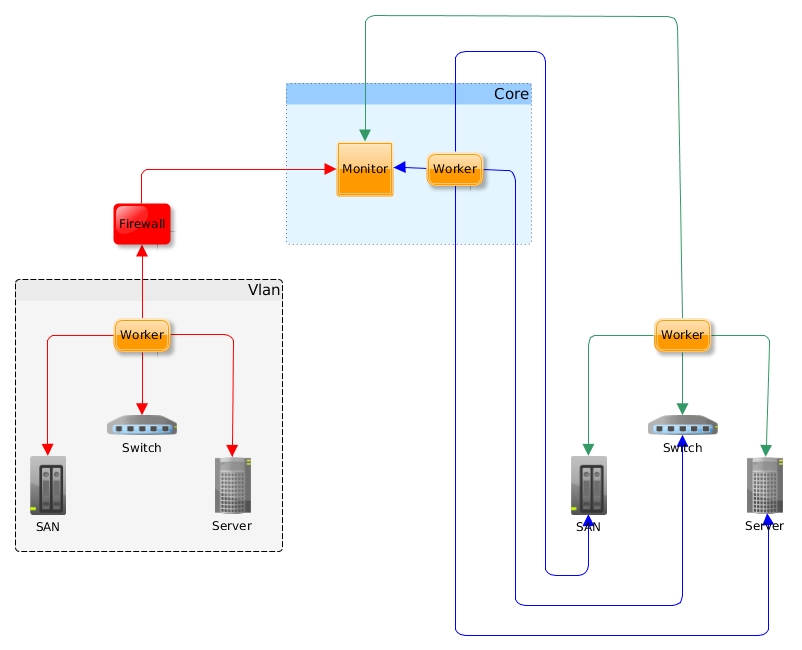
10. One step beyond! Ovvero della distribuzione. Qualcosa di più complicato? Per esempio Nagios in versione distribuita in modo da controllare ambienti molto complessi? Oppure Nagios in alta affidabilità?
Ok, mi sono giocato il prossimo anno di post.
Perché ho intitolato questo post “Brainstorming”? Perché se vi interessa, potete indicare nei commenti quali argomenti vorreste vedere trattati e quindi fornirmi qualche spunto nell’elaborazione dei prossimi post di questo corso.
Bon voyage…
Ah, giusto per dare un’idea…