Simple Traversal of User Datagram Protocol (UDP) Through Network Address Translators (NATs) (STUN), è un protocollo leggero che consente alle applicazioni di scoprire la presenza e la tipologia di NAT e firewall (frapposti, ndt) tra loro e l’Internet pubblica. Fornisce inoltre alle applicazioni la capacità di determinare gli indirizzi pubblici del Protocollo Internet (IP) loro allocati dal NAT. STUN funziona con molti tipi di NAT e non richiede da parte loro alcun tipo di comportamento speciale. In forza di ciò, consente a un’ampia gamma di applicazioni di funzionare attraverso l’infrastruttura NAT (pre)esistente.
E’ con l’abstract della RFC 3489 che riprendiamo in mano il filo del discorso intrapreso nella prima parte di questa lunga digressione, focalizzando fin da ora quale sia lo scopo pratico per il quale viene utilizzato il protocollo STUN (RFC 3489): consentire alle applicazioni che facciano uso di pacchetti UDP (STANDARD 00006) l’attraversamento di firewall e NAT (Network Address Translation – RFC 3022). Non si pensi, però, che STUN sia la soluzione a qualsiasi problema incontrato da un’applicazioni che sia segregata da un firewall o da un NAT. Tutt’altro, come viene ben evidenziato dal primo paragrafo della RFC 3489:
Questo protocollo non è una panacea per i problemi associati al NAT. Non consente connessioni TCP (STANDARD 00001) in entrata attraverso il NAT. Permette l’attraversamento del NAT in entrata per i pacchetti UDP, ma solo attraverso un sotto insieme dei (diversi ndt) tipi di NAT esistenti. In particolare, STUN non consente pacchetti UDP in entrata attraverso NAT simmetrici (definiti in seguito), comuni nelle grandi aziende. Le procedure di scoperata adottate da STUN sono basate sulle assunzioni (derivate, ndt) dal modo in cui NAT tratta UDP; queste assunzioni possono risultare non valide nella pratica nel momento in cui vengono introdotti nuove periferiche NAT. STUN non funziona quando viene utilizzato per ottenere un indirizzo (utile a, ndt.) comunicare con un nodo che sia dietro lo stesso NAT. STUN non funziona quando il server STUN non è nello stesso reame di indirizzi comuni condivisi. Per una discussione più completa discussione dei limiti di STUN, vedere la Sezione 14.
Tutto il discorso ruota quindi intorno al gioco di “invisibilità” introdotto dal NAT, specialmente quello simmetrico, come risulta evidente dalla definizione di quest’ultimo data nella prima parte di questo post:
Symmetric: Un Symmetric NAT è qualcosa di “unico”: come nel full nat, una connessione originata da una IP/PORTA interna verso un IP/PORTA esterna avrà una mappatura IP/PORTA pubblica sull’interfaccia esterna del router. La differenza risiede nella destinazione e nella “dinamicità” del mapping: ogni volta che o l’IP o la PORTA di destinazione cambiano, verrà utilizzato un mapping diverso sull’interfaccia esterna del router, ovvero una differente combinazione IP/PORTA pubblica. In più, solo l’host esterno che riceve un pacchetto può replicare con un pacchetto UDP verso l’host con indirizzo privato. Questa è una configurazione tipica di una rete aziendale.
E’ un po’ come il gioco della talpa in cui i pacchetti in uscita da un client dietro NAT simmetrico escono di volta in volta da una buca diversa, anche se si tratta sempre della stessa comunicazione, dello stesso soggetto emittente. In questo scenario, il NAT non è in grado di informare gli estremi di una comunicazione dei reali indirizzi e porte assunti da ognuno di questi nel corso di una stessa comunicazione, associazioni dinamiche e mutevoli. E sebbene siano state proposte linee guida per l’implementazione di protocolli NAT safe (RFC 3235), alcune fra le applicazioni più comuni non sono in grado di funzionare all’interno di un NAT. Perché diamo insieme un’occhiata ad alcuni passi della RFC 3235:
Con il NAPT (Network Address Port Translation, ndt), sia gli (indirizzi, ndt) IP che le porte di partenza e di arrivo (di un circuito di dati, ndt) (per TCP e UDP) vengono potenzialmente alterate dal gateway. Stante ciò, le applicazioni che passano solo l’informazione relativa al numero della porta (utilizzata per la connessione a un altro client o server, ndt) funzioneranno con il NAT di base, ma non con il NAPT.
E’ la differenza fra il NAT di base e il NAPT a giocare un ruolo fondamentale. Nel primo, viene alterato dal gateway (solitamente il firewall) unicamente l’IP con cui il client interno viene presentato sulla rete pubblica, mentre con il secondo viene modificato anche il numero di porta utilizzato per la connessione. Ed è sotto questa tipologia, il NAPT, che ricade il NAT simmetrico. Quali sono le tipologie di applicazioni che sono più inclini a non funzionare all’interno di un NAT simmetrico?
- Applicazioni Peer To Peer. Questo tipo di servizi vedono gli estremi di una connessione coinvolti in una rete in cui i client sono nello stesso tempo server. Per ciò che ci interessa ai fini di questa discussione, la differenza fra un client e un server può essere esemplificata nel seguente schema:
- Un client genera una connessione verso l’esterno. Non si attende di ricevere una connessione originata dall’esteno a lui diretta;
- Un server attende una connessione originata dall’esterno, alla quale rispondere. Un server, quindi, rimane in ascolto (binding) su una tupla IP/PORTA, che sarà il punto di arrivo di una connessione iniziata da un client.
In questo scenario, in cui il client è anche server, un NAT simmetrico che prevede una mappatura dinamica degli IP e delle porte ostacola la raggiungibilità univoca dei servizi: dietro al NAT potrebbero esservi una moltitudine di client che di volta in volta assumono la tupla IP/PORTA del client/server i cui servizi si vorrebbe raggiungere;
- Applicazioni che richiedono l’utilizzo del protocollo IPSec (Internet Protocol Security, RFC 2401) in modalità end-to-end. I presupposti per cui non può essere utilizzato IPSec quando uno dei due estremi della connessione è all’interno di un NAT sono simili, come viene evidenziato nella RFC 2709, dedicata all’implementazione di IPSec in modalità tunnel combinata con il NAT :
- Le applicazioni che incorporano informazioni inerenti al reame (di indirizzi privati, ndt) nel payload richiederanno un application level gateway (ALG), affinché il payload abbia senso in entrambe i reami. Tuttavia, le applicazioni che richiedono l’ausilio di un ALG per il routing non possono conseguire una sicurezza end-to-end a livello di applicazione.
Torniamo alla RFC 3235, per capire il perché di questa limitazione:
Le applicazioni dovrebbero, quando possibile, usare dei nomi a dominio pienamente qualificati (FQDN, ndt), piuttosto che gli indirizzi IP, quando fanno riferimento a punti finali (gli estremi di una comunicazione, ndt) IP. Applications should, where possible, use fully qualified domain names. Quando gli estremi sono posti su lati diversi di un gateway NAT, agli indirizzi privati non deve essere consentito di raggiungere l’altro estremo (della connessione, ndt).
Una ragione per questa limitazione viene fornita dalla stessa RFC 3235:
Ad aggravare ulteriormente il problema è la possibilità che vi siano indirizzi duplicati fra i due reami. Se un server offre un collegamento contenente un indirizzi IP privato, tipo 192.168.1.10, la pagina referenziata (si sta facendo riferimento, come esempio, a un server web che offra collegamenti a pagine poste su macchine all’interno del suo reame di indirizzi privati, ndt.) la pagina referenziata può risolvere a un sistema sulla rete locale sul quale si trova il browser (che evidentemente si trova su un altro spazio di indirizzi privati, ndt), ma questo sarebbe un server completamente differente. La confusione che ne risulterebbe per gli utenti finale sarebbe significativa. Le sessioni che coinvolgono implementazioni multiple del NAT (nell’esempio il server web è su una reta in NAT, il client su una diversa rete in NAT), sarebbero eccezionalmente vulnerabili a problemi di riutilizzo di indirizzi di questo tipo.
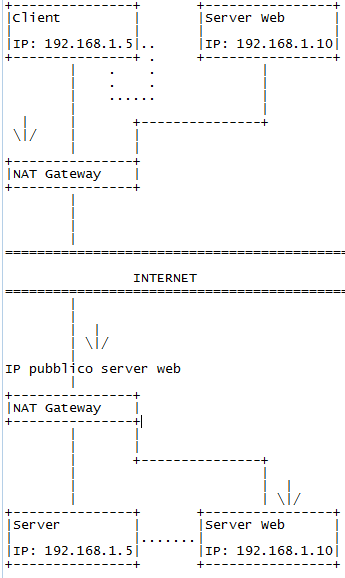
Per capire intuitivamente il problema, diamo un’occhiata al seguente diagramma: Notato qualcosa? In effetti le due reti private hanno, possono avere, la stessa classe di indirizzi, anche lo stesso subnetting, il che porta a uno spiacevole equivoco nel routing dei pacchetti. Se il client .5 della prima rete (quella più in alto nello schema) richiede al web server 192.168.1.10 della rete più in basso una pagina che si trova su una macchina nella stessa sotto rete del server, 192.168.10.5, il server istruirà il client della prima rete a chiedere una pagina alla macchina 192.168.1.5. Ora, attenzione a ciò che viene detto nella RFC 1918:
Un’azienda che decida di utilizzare indirizzi che non facciano parte dello spazio di indirizzamento definito in questo documento (ovvero voglia utilizzare indirizzi privati, ndt), può farlo senza alcun coordinamento con lo IANA o un Internet registry. Lo spazio di indirizzamento può essere così utilizzabile da molte aziende. Gli indirizzi all’interno di questo spazio privato di indirizzamento saranno unici solo al’interno dell’azienda, o del gruppo di aziende che scelgano di cooperare in questo spazio in modo da comunicare l’una con l’altra all’interno della loro internet privata.
Cosa significa?
Semplicemente che chiunque, al di qua di un router, può utilizzare per la connettività interna alla propria rete degli indirizzi privati, senza alcun coordinamento con le autorità che gestiscono le numerazioni pubbliche. Al contempo, però, gli indirizzi privati non sono “routabili”, ovvero non possono uscire al di là del gateway che collega la rete privata, per esempio una rete aziendale o domestica, a internet.
Tutto ciò porta a due considerazioni interessanti:
- L’orizzonte di visibilità di un indirizzamento privato ha come proprio limite il gateway di rete. Semplificando, le macchine possono vedere gli indirizzi privati solo fino al router, al di fuori del quale non hanno cognizione di altri indirizzamenti privati. Quindi, 192.168.1.5 significa una precisa macchina nella stessa rete del client che sta cercando di interrogarla, non su qualche altra rete privata remota;
- Più reti private possono utilizzare gli stessi indirizzamenti privati, senza che questo porti a un qualche equivoco. L’indirizzo 192.168.1.5 è “qui”, all’interno della prima rete, per le altre macchine della stessa rete, ma è “qui” anche per le macchine della seconda rete, con due “qui” differenti ma coerenti, ognuno all’interno del proprio spazio di indirizzamento privato.
Date queste premesse, uno sguardo allo schema precedente rende bene l’idea del problema: se il client 192.168.1.5 della prima rete interroga un web server sulla seconda rete, chiamando il suo indirizzo pubblico, e questo rimanda a un collegamento a una macchina con indirizzo 192.168.1.5 nella propria sotto rete, qui, proprio qui, sorge un equivoco: il client 192.168.1.5 della prima rete si vedrà istruire dal web server della seconda rete a cercare una risorsa all’indirizzo 192.168.1.5. Il problema risiede nella limitatezza dell’orizzonte: il server intende puntare alla macchina 192.168.1.5 sulla seconda rete, ma per il client della prima rete 192.168.1.5 ha senso solo nella propria rete. Ergo, il client tenta di interrogare se stesso alla ricerca di una risorsa che è presente solo sulla rete privata remota.
Ecco l’equivoco: ognuno interpreta gli indirizzi privati “a casa propria”, non vede, non conosce altro che non sia sulla propria rete.
Una delle metologie approntate come ausilio per quelle applicazioni che non possono nativamente operare attraverso un NAT è l’Application Level Gateway (ALG), agenti in grado di interfacciarsi con i gateway NAT e consentire ai programmi in funzione su un host di contattare la propria controparte su un host appartenente a un reame di indirizzi differenti. L’implementazione di un ALG può differire notevolmente di situazione in situazione, ponendosi in dialogo diretto con il gateway NAT per gestire gli stati delle connessioni, modificare il payload dei pacchetti per riscrivere la mappatura degli indirizzi e, comunque, garantire tutte quelle operazioni necessarie a mettere in comunicazione servizi appartenenti a reti differenti (end-to-end). Questo tipo di soluzione ha un indubbio vantaggio: non richiede alcuna modifica ai client, ponendosi in maniera del tutto trasparente tra le applicazioni e il NAT. Di contro, la sua implementazione pone dei problemi soprattutto per quanto riguarda la scalabilità e affidabilità di esercizio.
Una soluzione più interessante è rappresentata dallo sviluppo del Middlebox Communications (MIDCOM) protocol (RFC 3304), un protocollo che consente, tramite l’utilizzo di agenti, connessioni fidate (trusted) con le Middlebox (RFC 3303).
Messa in questi termini, la questione appare inintellegibile.
Prima di tutto, cosa è una Middlebox?
In sostanza, si tratta di un apparato di intermediazione di rete che implementa un servizio, come per esempio un NAT o un firewall, ma con una particolarità che lo rende unico rispetto a un tradizionale firewall o NAT: è in grado di delegare in parte o tutta la logica di funzionamento dell’apparato a uno o più agenti MIDCOM.
Ora, pensate a un’applicazione in grado di utilizzare un agente MIDCOM per controllare un NAT e gestirne dinamicamente le funzionalità, in modo da aprirsi dei varchi per consentire le comunicazioni end-to-end tra reami di indirizzamento differenti.
A questo punto, gli intermediari di rete diventano flessibili, si adattano alle esigenze delle applicazioni, superano le rigidità imposte dai protocolli.
Interessante, vero?
Interessante ma poco fattibile. Una rete MIDCOM aware implica la sostituzione degli apparati tradizionali con le nuove versioni in grado di supportarne il protocollo e, specialmente in ambienti enterprise ciò implica un investimento e un grado di ristrutturazione non sempre affrontabili. Inoltre, vi sono casi in cui gli agenti MIDCOM non possono avere visibilità su tutti gli apparati di rete coinvolti, come nell’esempio citato nella RFC 3489: molti provider utilizzano un NAT sulle linee dei clienti residenziali, i quali a loro volta usufruiscono di un secondo NAT sulla loro rete privata. Se l’utente finale può avere visibilità e controllo su una middlebox MIDCOM nella rete privata, agli agenti installati sulle loro macchine non sarà dato alcun controllo sulle middlebox che gestiscono il NAT direttamente sulle infrastrutture del provider stesso.
E’ chiaro che una soluzione univoca per ogni possibile scenario è difficilmente applicabile, per differenti ordini di motivazioni: costi, flessibilità, sicurezza, il che lascia uno spazio progettuale per soluzioni specifiche, pensate e sviluppate per facilitare il funzionamento di singoli protocolli all’interno di ambienti in NAT.
STUN è proprio questo, in termine burocratese è un “facilitatore”, ma questo sarà l’argomento della terza puntata di questo lungo post.
 Ahem, come dire.
Ahem, come dire. appena sbloccato dai ragazzi dei
appena sbloccato dai ragazzi dei